Visual Reasoning Benchmark
Clock Bench
ClockBench evaluates whether models can read analog clocks - a task that is trivial for humans, but current frontier models struggle with.
Leaderboard
| Rank | Model | Accuracy | Lab |
|---|---|---|---|
| Human Baseline | 90.7% | ||
| 1 | GPT-5.6 Sol Max | 66.7% | OpenAI |
| 2 | Claude Opus 5 Max | 60.7% | Anthropic |
| 3 | GPT-5.4 High | 50.6% | OpenAI |
| 4 | GPT-5.5 High | 46.1% | OpenAI |
| 5 | Qwen 3-VL 235B Instruct | 39.4% | Alibaba |
| 6 | Claude Fable 5 | 35% | Anthropic |
| 7 | Gemini 3.1 Pro | 32.2% | |
| 8 | Gemini 3.5 Flash | 31.1% | |
| 9 | Gemini 3 Pro | 28.9% | |
| 10 | Grok 4.5 | 21.7% | xAI |
| 11 | Gemini 2.5 Pro | 18.9% | |
| 12 | GPT-5.2 High | 15% | OpenAI |
| 13 | Gemini Robotics ER 1.5 | 15% | |
| 14 | Claude Opus 4.7 | 15% | Anthropic |
| 15 | o3 Pro | 14.4% | OpenAI |
| 16 | Qwen 3-VL 235B Thinking | 14.4% | Alibaba |
| 17 | o3 High | 12.2% | OpenAI |
| 18 | Gemini 2.5 Flash | 11.1% | |
| 19 | GPT-5 High | 11.1% | OpenAI |
| 20 | GPT-5 Pro | 11.1% | OpenAI |
| 21 | Mistral Medium 3.1 | 10% | Mistral |
| 22 | Claude Opus 4.6 | 8.9% | Anthropic |
| 23 | GPT-5 Mini | 8.9% | OpenAI |
| 24 | Claude Opus 4.1 | 8.3% | Anthropic |
| 25 | Claude Sonnet 4.5 | 7.2% | Anthropic |
| 26 | Qwen 2.5-VL 72B | 6.1% | Alibaba |
| 27 | Claude Sonnet 4 | 6.1% | Anthropic |
| 28 | GTP-4o | 5% | OpenAI |
| 29 | GTP-5 Nano | 3.9% | OpenAI |
| 30 | Grok 4 Fast | 3.9% | xAI |
Results Summary
Despite frontier models showing strong reasoning skills, mathematical ability, and visual understanding on multiple benchmarks, they seem to be struggling at reading analog clocks for now.
One hypothesis might be that this task sets a high bar for doing reasoning within the visual space (as opposed to text space).
More research is likely needed to understand if these capabilities can be obtained by scaling existing paradigms, or a novel approach is required.
Dataset
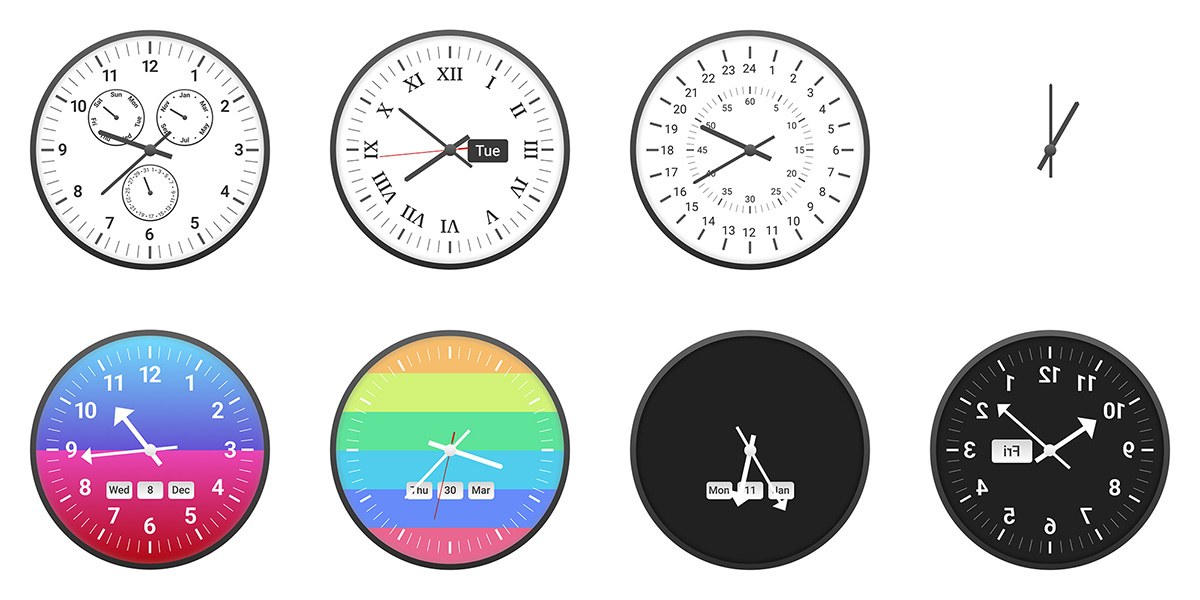
Sample Clocks
Few examples of clocks that we used in the benchmark.
Questions
- Reading TimeModels are asked to determine whether a given clock shows a valid time. If valid, they should report the hours, minutes, seconds, date, month, and day of the week (based on what is present), in a structured JSON format.
- Adding or Subtracting TimeModels are asked to add or subtract varying amounts of time.
- Rotating HandsModels are asked to rotate one of the hands (hour, minute, or second) by a specified angle, clockwise or counterclockwise.
- Shifting Time ZoneModels are asked to assume they are in New York during summer and report the corresponding time in various locations worldwide.
Try Yourself
Interesting in trying out ClockBench?
A small public dataset and sample evaluation code is available to everyone.
Please reach out to [email protected] with ideas, suggestions, questions or any other inquiries.